The phrase data virtualisation still matters. It describes a real architectural capability and many vendors continue to use it. But for engineering teams building in CI/CD, ephemeral environments, and fast release cycles, the term no longer describes the whole job. It captures one technique. It does not capture the complete outcome teams now need.
A useful way to position it: data virtualisation is not wrong. It is narrower than the modern requirement.
1) What “data virtualisation” originally solved
In enterprise data architecture, Denodo defines data virtualization as a single data-access layer built from logical or virtual representations of physical sources, enabling real-time access across heterogeneous systems. In testing, that concept evolved into test data virtualization: lightweight, on-demand copies intended to avoid the time, cost, and storage overhead of repeatedly cloning full environments.
Broadcom’s earlier CA Virtual Test Data Manager materials make that framing explicit: they describe virtual copies of test data, on demand, in seconds, with a minimal footprint and self-service access for testers. Delphix still uses similar language today, describing how virtualization can produce ephemeral copies and virtual databases while enabling refresh and rollback workflows.
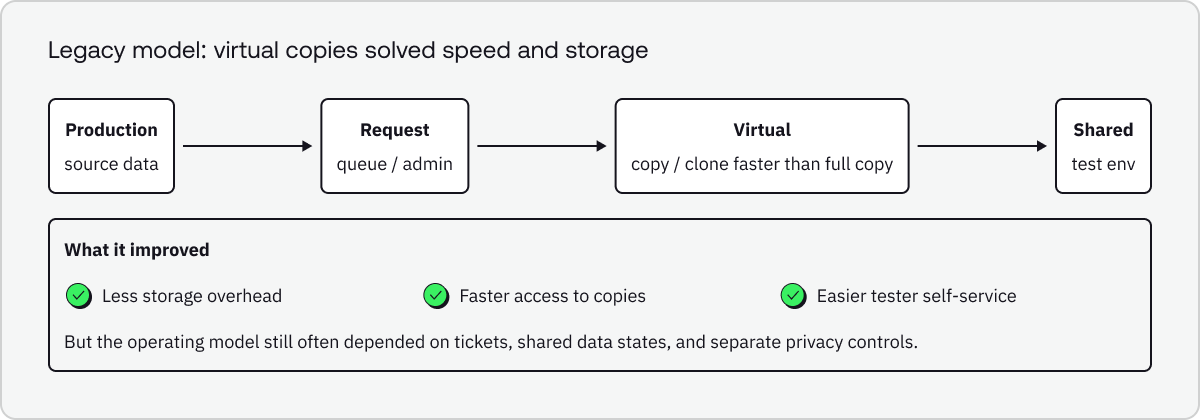
2) Why that framing is too narrow now
Modern engineering teams do not just need access to a copy of data. They need the right data, in the right shape, with the right privacy controls, delivered at the right moment in the delivery workflow.
That broader requirement shows up clearly in current product documentation. Redgate describes test data management as the process of providing DevOps teams with test data, typically including copying production data, anonymization or masking, and sometimes virtualization. Tonic Structural emphasizes sensitive data detection, transformation, safe dataset creation, and CI/CD integration so generated data is available on demand. Delphix argues that modern teams must move past legacy TDM practices and automate data delivery to CI/CD pipelines via unified APIs.
The privacy dimension matters too. NIST’s guidance on de-identification notes that organizations may choose models such as publishing synthetic data, and explicitly warns that tools which merely mask personal information may not provide sufficient functionality for de-identification. In other words, modern test data workflows are increasingly about governed data transformation, not only cloning or virtual access.
Old question: How do we virtualise test data faster?
Better modern question: How do we automate compliant, production-like test data delivery across every environment and pipeline?
3) The modern model: test data automation
Test data automation is the more useful umbrella term because it describes the full lifecycle. It covers not just how data is accessed, but how it is discovered, transformed, generated, provisioned, refreshed, audited, and reused.
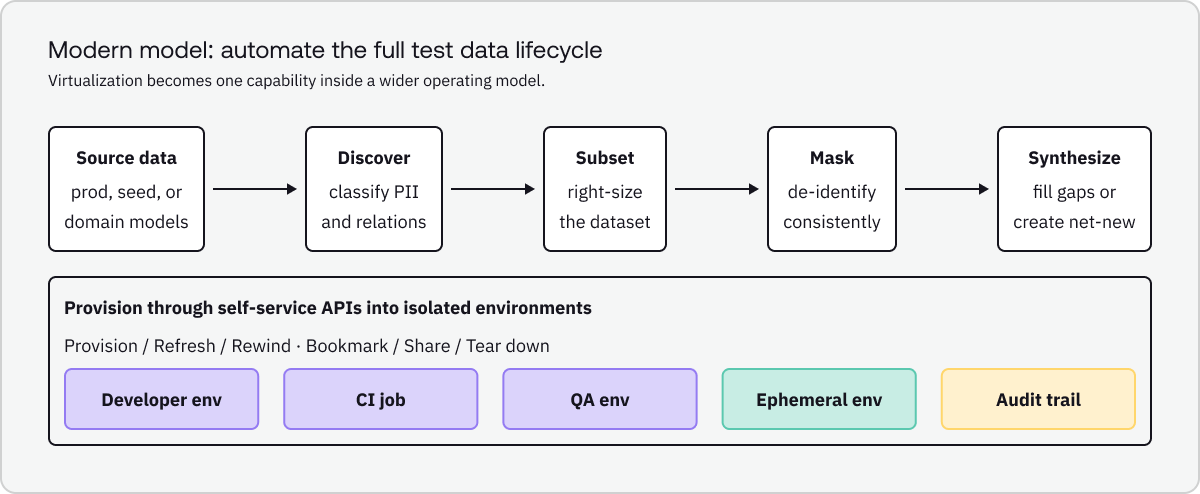
The capability stack
A practical modern stack usually includes:
- Discovery and classification to find sensitive fields and map relationships.
- Subsetting to create smaller, representative datasets while preserving referential integrity.
- Masking or de-identification to protect sensitive data in non-production use.
- Synthetic generation when real production-like data is unavailable, insufficient, or too risky.
- Provisioning APIs and self-service workflows so developers, testers, and pipelines can request data without waiting on tickets.
- Refresh, rewind, share, and tear-down controls for fast iteration in isolated environments.
- Governance so teams know what data was provisioned, how it was transformed, and where it was used.
4) Data virtualisation vs. test data automation
5) The practical takeaway
If your strategy is still described mainly as data virtualisation, you may be describing only one layer of the value stack. The language modern teams respond to is broader because their requirement is broader:
- safe by default
- available on demand
- small enough to move fast
- realistic enough to test properly
- easy to refresh and reset
- designed to fit pipelines, not tickets
That is why test data automation is the better modern framing. It captures the outcome engineering teams actually care about: trusted test data delivered continuously, not just virtual copies created quickly.
Does this mean data virtualisation is obsolete?
No. It remains a real and valuable capability, and some vendors continue to use the term actively. The point is that virtualization is now part of a broader automation model, rather than the whole story.
Why include synthetic data in the comparison?
Because modern privacy and usability requirements often go beyond simple masking. NIST explicitly includes synthetic data among the models agencies may choose for sharing and warns that masking alone may be insufficient for de-identification.
What is the most defensible positioning statement?
Data virtualisation is one capability; test data automation is the modern operating model. That framing is strong without overclaiming that the old term has disappeared entirely.