Agentic QA (AI agents applied to quality assurance) promises autonomous testing, fewer bugs, and faster releases. The reality is more complex, but teams that combine deterministic testing with agentic exploration and strong data achieve better release confidence and delivery performance.
Everyone loves the demo: an AI agent opens the product, clicks through a flow, finds a defect, and drafts a bug report. It looks like the future. The problem is that many teams still treat agentic QA as test automation with an LLM glued on. The data in the 2025 Google Cloud DORA Report, which provides insights into AI’s role in software development, shows a more nuanced and much more interesting reality.

TL;DR - Key takeaways
- Agentic QA augments deterministic testing instead of replacing it.
- Context (test data, platform quality, telemetry) matters more than raw agent autonomy.
- More clicks and screenshots are not better QA without higher signal quality.
- Human QA moves up-stack, focusing on risk judgment and release decisions.
Agentic QA uses AI agents to explore applications, reproduce bugs, and generate quality signal, while deterministic tests still validate known behavior and contracts.
Why does agentic QA matter now?
AI is already mainstream in software development, with the majority of technology professionals using AI tools. DORA's 2025 report says 90% of technology professionals now use AI at work and more than 80% believe it has increased their productivity.
Quality engineering is behind in maturity. Capgemini's World Quality Report 2025-26 says 43% of organizations are experimenting with GenAI in QA, while only 15% have scaled it enterprise-wide.
In practice, this means the market is full of impressive demos, but far fewer teams have a durable operating model for agentic QA. As one major research program puts it: AI does not fix a team, it amplifies what is already there.
"AI does not fix a team; it amplifies what is already there."
If your testing, data, and platforms are brittle, agentic QA amplifies that brittleness. If your foundations are strong, agentic QA amplifies coverage, learning, and speed.
Agentic QA - it’s all about trust
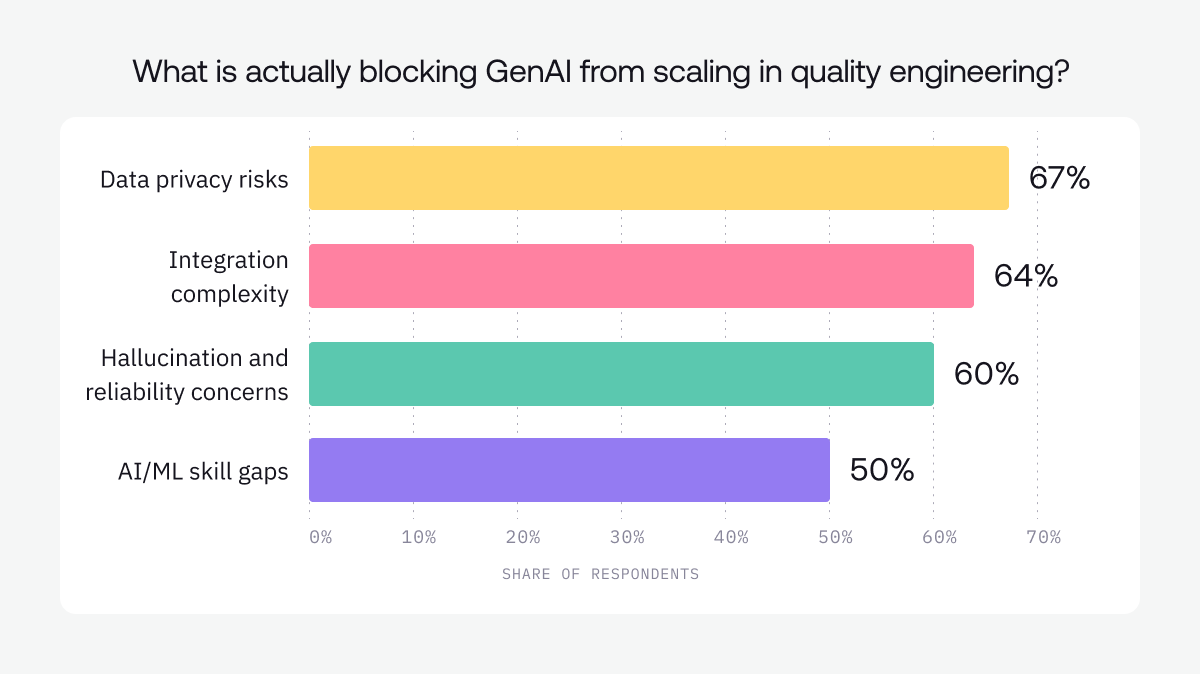
The real issue with the usefulness of agentic QA is less about whether AI can perform tasks quicker than a human and more about whether teams can integrate, verify, govern, trust, and rely on that output. In the World Quality Report's 2025 press release, organizations reported an average 19% productivity boost from GenAI in quality engineering, but the same research surfaced major blockers: data privacy risks, integration complexity, hallucination and reliability concerns, and skill gaps.
Based on what’s actually happening in the industry right now and what experts are seeing in practice, I’ll move on to the biggest misconceptions about agentic QA, that keep coming up, and why they don’t hold up anymore:
Misconception 1. Agentic QA will replace deterministic testing
It won’t. Deterministic tests still provide the contract for known behavior and are the system of record for how the software must work.
When DORA examined AI adoption in 2024, a 25% increase in AI adoption was associated with a 1.5% decrease in delivery throughput and a 7.2% reduction in delivery stability. In 2025, the picture improved slightly, and a more positive relationship emerged among AI adoption, software delivery throughput, and product performance. But software delivery stability was still negatively affected as a result of AI adoption.
The DORA report shows that rapid AI adoption can increase change volume, but teams without strong automated tests, mature version control, and fast feedback loops pay for that speed in instability. So the right model does not simply come down to either scripts or agents. The right model is deterministic coverage for known behavior, then agentic exploration for unknown unknowns such as novel user paths, brittle workflows, environment drift, and messy edge cases.
Deterministic tests answer the question: Does this code still satisfy the contract we agreed on?
Agentic QA answers the question: where are we still fragile in ways we did not fully anticipate?
Misconception 2. More autonomy automatically means better QA
More autonomy in QA is not a virtue in itself. It is a multiplier. If your inputs are weak, more autonomy just multiplies noise.
Most teams do not have an autonomy problem. They have a context problem. The World Quality Report 2025-26 says 60% of organizations struggle with secure, scalable test data, and 58% struggle to adopt AI-powered tools in QA. Synthetic data in testing jumped from 14% in 2024 to 25% in 2025. That is not a story about magical agents. It is a story about teams scrambling to fix inputs because better data, not smarter models, has become the real bottleneck.
DORA’s platform research points in the same direction. By 2025, 90% of organizations reported using an internal developer platform, and 76% had dedicated platform teams. Crucially, DORA finds that when platform quality is high, AI has a strong and positive effect on organizational performance. When platform quality is low, AI’s effect is negligible.
Autonomy does not rescue a weak platform. It just exposes it faster. In practical terms, if your agent lacks trustworthy test data, rich product context, stable environments, clear policy boundaries, and solid observability, turning up autonomy will not give you better QA. It will mostly amplify churn, pseudo-bugs, and dashboard theater.
Misconception 3. If an agent can click through the app, it is doing QA
The industry has fallen in love with the screenshot of an agent clicking through a happy-path demo. But clicking is not QA. Recognizing and communicating meaningful risk is QA.
DORA’s 2026 qualitative analysis of 1,110 open-ended responses from Google software engineers describes a very real verification tax: time saved during generation is often re-spent on auditing and reviewing AI output. One engineer puts it bluntly: “AI feels productive, but it also creates more babysitting and review work”. That is not net-new assurance. That is a shifted cost center.
GitLab’s 2025 Global DevSecOps survey tells the same story in numbers. Only 37% of respondents would trust AI to handle daily work tasks without human review, and 73% have already been burned by code produced through loose, ‘vibe’ coding. If teams do not trust AI in core development workflows, there is no reason to assume they will blindly trust agents to drive QA. Any agentic QA tool that optimizes for activity instead of signal will run straight into this trust ceiling.
Navigating the UI is the easy part for an agent. The hard part is telling a team what actually failed, why it matters in business and reliability terms, and how to reproduce it in a way engineers can act on. That is where most current “clickbot” demos quietly run out of road.
And remember, teams were already drowning in noisy signal before agents showed up. A developer survey found that 59% of engineers deal with flaky tests monthly, weekly, or even daily. A Chromium CI case study showed that if teams simply suppressed failures labeled as flaky, they would miss about 76.2% of true regression faults. A bad signal is costly, but bluntly muting noisy signal is even more dangerous.
The implication is clear: agentic QA that generates more screenshots, more logs, and more pseudo-bugs without dramatically improving diagnosis will not make releases safer. It will slow teams down, erode trust, and push more work onto the very humans these tools were supposed to help.
Misconception 4. Agentic QA makes human QA obsolete
The “AI will replace QA” narrative makes for a dramatic keynote slide. It is not what the data shows on the ground.
GitLab’s 2025 survey found that 88% of respondents believe there are essential human qualities that agentic AI will never fully replace. The World Quality Report goes further: GenAI is now the top-ranked skill for quality engineers at 63%, but core quality engineering skills sit right behind at 60%, and soft skills still matter to 51% of respondents. That looks less like a sunset curve and more like a role in the middle of an upgrade.
To me, this is the profile of QA moving up the stack, not disappearing. Less manual repetition. More risk judgment, release confidence, communication, governance, and product intuition.
The future QA leader is not the person who can personally step through every regression test before a release. It is the person who knows where the product is fragile, which failure patterns matter for customers and regulators, and which issues should actually change a launch decision. Agentic QA does not replace that person. It makes their judgment more central.
Misconception 5. Agentic QA is just a better end-to-end testing tool
DORA’s 2026 analysis shows that AI’s most visible impact today spans code generation, information seeking, code review, and testing. In other words, AI is already threaded through how we write, understand, and change software, not just how we click through a UI.
On the quality side, the World Quality Report finds that 94% of organizations review production data, yet nearly half still struggle to translate those insights into actionable quality improvements. Teams are not starved of signal. They are starved of the ability to turn that signal into better tests, faster triage, and safer releases.
That is why I see the real opportunity for agentic QA as something bigger than auto-generated end-to-end scripts. The interesting work is in connecting production signal to reproduction, triage, root cause analysis, test design, and tight feedback into the development system.
The best agentic QA systems will not just run flows faster. They will help the entire organization learn faster from failures and bake that learning back into code, tests, and platforms.
Bottomline: A practical operating model for agentic QA
1. Protect the deterministic baseline. Unit, integration, contract, and regression tests remain the system of record for known behavior.
2. Aim agents at uncertainty. Use them for exploratory journeys, risky pull requests, bug reproduction, environment drift, and change-heavy surfaces.
3. Feed agents context, not just prompts. Good test data, telemetry, architecture notes, policy constraints, and known-good workflows matter more than clever demos.
4. Measure signal quality, not activity. Track valid bug yield, false-positive rate, time to reproduce, escaped defects, and how often agent findings survive engineer review.
5. Keep humans on the judgment boundary. Let agents expand the search space and compress toil; let people decide severity, tradeoffs, and release risk.

The point of agentic QA is not to cram more autonomous agents into your pipeline. It is to produce quality signal that is trustworthy, observable, and economically meaningful.
CISQ estimates that poor software quality cost the U.S. at least 2.41 trillion dollars in 2022, including about 1.52 trillion in accumulated technical debt. At that scale, shipping faster without better signal is not innovation. It is an invisible tax on your business that teams can no longer afford to pay.
Sources
Based on data and findings from recent DORA reports, World Quality Report highlights and press releases, GitLab Global DevSecOps surveys, academic studies on flaky tests, and cost of poor software quality analyses.
[DORA 2025] Google Cloud, 'Announcing the 2025 DORA Report' (Sept. 23, 2025). https://cloud.google.com/blog/products/ai-machine-learning/announcing-the-2025-dora-report
[DORA Platform] DORA, 'Platform engineering' (updated Jan. 12, 2026). https://dora.dev/capabilities/platform-engineering/
[DORA 2026 Insight] DORA, 'Balancing AI tensions: Moving from AI adoption to effective SDLC use' (Mar. 10, 2026). https://dora.dev/insights/balancing-ai-tensions/
[DORA 2024] Google Cloud, 'Announcing the 2024 DORA report' (Oct. 22, 2024). https://cloud.google.com/blog/products/devops-sre/announcing-the-2024-dora-report
[WQR 2025-26] Capgemini, 'World Quality Report 2025-26' highlights page. https://www.capgemini.com/insights/research-library/world-quality-report-2025-26/
[WQR 2025 Press Release] Sogeti / OpenText / Capgemini, 'World Quality Report 2025: AI adoption surges in Quality Engineering, but enterprise-level scaling remains elusive' (Nov. 13, 2025). https://www.sogeti.com/newsroom/world-quality-report-2025/
[GitLab 2025 Survey] GitLab, 'Survey Reveals the AI Paradox' press release (Nov. 10, 2025). https://about.gitlab.com/press/releases/2025-11-10-gitlab-survey-reveals-the-ai-paradox/
[Chromium CI Study] Guillaume Haben et al., 'The Importance of Discerning Flaky from Fault-triggering Test Failures: A Case Study on the Chromium CI' (2023). https://arxiv.org/abs/2302.10594
[Flaky Tests Survey] Oliver Parry et al., 'A Survey of Flaky Tests' (ACM TOSEM, 2021). DOI: 10.1145/3476105
[CISQ 2022] CISQ, 'The Cost of Poor Software Quality in the U.S.: A 2022 Report.' https://www.it-cisq.org/the-cost-of-poor-quality-software-in-the-us-a-2022-report/