Validate software, migrations, and AI agents before they touch production
Synthesized creates governed, production-realistic scenarios from sensitive enterprise systems, enabling safe enterprise application release, SAP transformation and AI-agent validation at scale.
Trusted by leading engineering, data & AI teams
Why Synthesized?
Pre-production data plane for enterprise AI
Learn enterprise systems
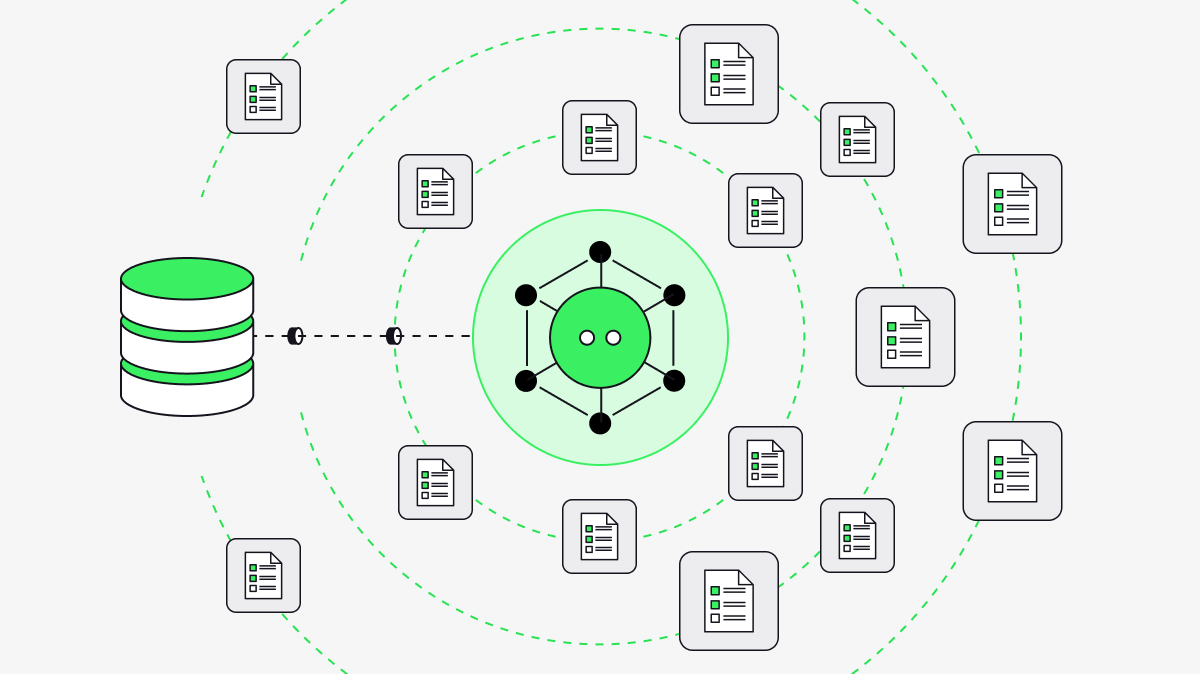
Synthesized learns schemas, relationships, business logic, workflow state, and permissions across sensitive enterprise systems; turning production data into governed pre-production scenarios.
Create governed scenarios
Generate production-faithful scenarios at any scale while preserving structural fidelity and referential integrity, and transforming sensitive values safely.
Feed validation workflows
Deliver governed scenarios into CI/CD, testing, migrations, evals, and AI-agent workflows so teams can validate software and enterprise change before production.
Enforce policy by default
Apply privacy, compliance, and access controls automatically so teams can work with realistic enterprise state without exposing production data.
01
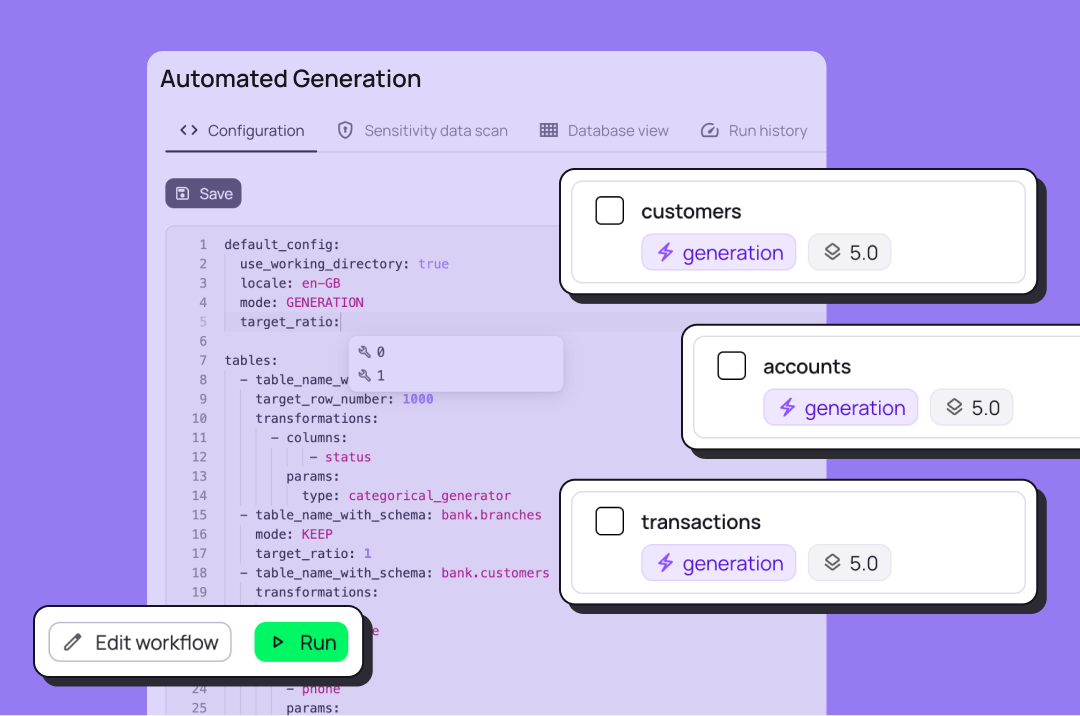
Specify requirements
Write data requirements with the help of LLM in a YAML config file for a database or using Python DSL for a dataset.
02
Create workflow
Create a data transformation job, check data categorization and access rights.
03
Run job
Run job as part of CI/CD or data pipeline to generate data in the destination that meets the requirements.
Continuous Data Availability for Test Automation & Agentic AI Workflows
Test data generation for any development and QA use-case
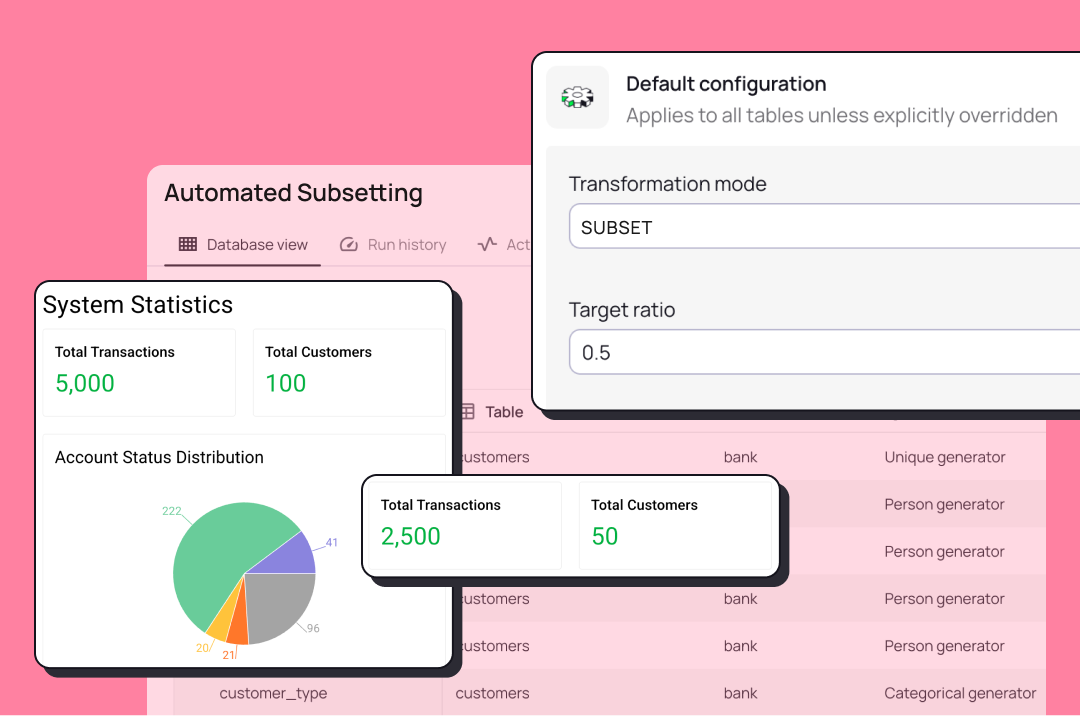
Create datasets representative of real-world scenarios at any size on-demand.
Streamline the database generation process with the LLM, ensuring the availability of high-quality data for testing while minimizing manual effort and accelerating development cycles.
Provide teams with access to a subset of data that is relevant to their roles or tasks, without exposing the entire database. Use GenAI to generate specific databases for complex use-cases.
Selectively masks sensitive information within the subset for an optimal balance between data security and usability.
Save over 70% in costs per application dev & test lifecycle. Make your database provisioning cloud-native using Synthesized database generation, masking and subsetting engine that runs in Kubernetes. Seamless integration with testing frameworks enables efficient automation, while continuous learning ensures ongoing improvement, resulting in faster, higher-quality software releases.
Automate test data management with AI
With AI algorithms analyzing requirements and patterns, production-like data is produced, ensuring comprehensive test coverage. With the help of GenAI sensitive data is protected through intelligent masking techniques while maintaining data integrity. Test data is dynamically refreshed to reflect changes in the application, and predictive maintenance anticipates future testing needs.
Identify bugs earlier, for faster, more stable releases
Ensure rapid detection, root cause analysis, and resolution of data quality issues, enabling quick mitigation before impacting your operations. Feel confident in your application by finding the root cause before anyone else.
Accelerate cloud and application migration
Overcome fragmented systems with a unified test data platform. Synthesized breaks down data silos, providing seamless integration and a consistent approach to test data management. Flaky tests undermine confidence in automation. Synthesized ensures your test data is stable and reliable, aligning perfectly with your test automation frameworks for consistent results.
One platform Supporting Complex Enterprise Database Needs
SAP HANA testing is often slowed down by complex, tightly integrated data that’s difficult to validate without impacting business continuity. Synthesized provides SAP-native test data management and automation to deliver reliable, production-scale data across SAP and non-SAP systems.
Deliver production-scale, compliant test data for every testing scenario
Validate end-to-end processes across SAP HANA and connected applications
Reduce risk and accelerate SAP changes with reliable test data
Stream PostgreSQL database preparation for development and testing
Synthesized provides the only AI-driven database masking, subsetting, and generation for PostgreSQL, tailored for application development and testing teams.
Automate the creation of databases that closely mirror production environments.
Enhance security and compliance by intelligently masking sensitive data, ensuring that personally identifiable information is protected.
Automate SQL Server test data provisioning
Synthesized optimizes SQL Server development cycles by efficiently identifying performance bottlenecks and data anomalies, crucial for handling large transaction volumes and complex queries.
Ensure every possible data scenario is covered by your test data.
Identify the "unknown unknowns", to accelerate release cycles and deliver with fewer bugs.
Automated test data provisioning for Oracle
Synthesized for Oracle databases enhance environments that handle high-volume transactions and complex production pipelines. Minimize downtime and optimize development with the right data, not all the data.
Manage complex Oracle-specific data types and relationships with Synthesized automated data generation
Intelligent masking for PII risk discovery.
Enhance Salesforce development with privacy-preserving snapshots
Synthesized enables rapid, reliable Salesforce application development with privacy-preserving snapshots for QA and development. Quickly identify and resolve issues, minimizing operational disruptions and enhance application robustness before release, not after.
Automated, comprehensive data coverage for any use-case
Protect sensitive customer information with AI-driven data masking techniques, ensuring compliance with codified regulatory rules
Partners & integrations
Built to work where you work
We understand that today’s production data pipelines and development environments are complex and dynamic. So while you can use Synthesized to generate production-like data for your specific POC, it also works with your specific technologies.
Cloud
Create production-like data in your cloud tenant
Deploy instantly, supercharge effortlessly, and accelerate initiatives with seamless cloud marketplace integrations. Our “Data as Code” approach makes it easy for anyone to be a data engineer.