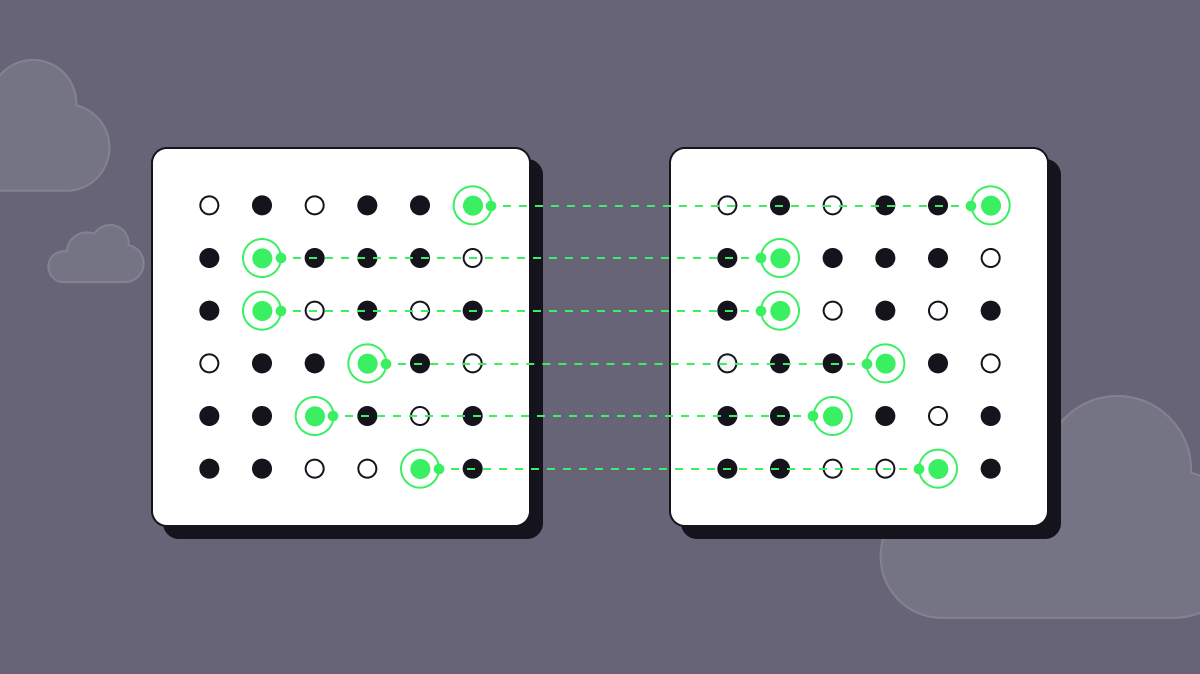
In the rapidly evolving world of software development, a single overlooked flaw can spell disaster. The quest for robustness hinges on comprehensive testing, where the crucible is the diversity and quality of test data. Software testing, once a rigid routine, is now poised for a transformation.
Generating data that mirrors the complexity of production is no small feat. Traditional methods often fall short, leaving gaps that real-world variances eagerly exploit. The solution lies in a paradigm shift, employing AI to bridge the distance between simulated environments and the unpredictable tide of live user interaction.
This article delves into the intersection of artificial intelligence and software testing, illustrating how AI can be a game-changer in producing varied and realistic test datasets. Discover the futuristic tools enhancing data generation, learn to incorporate real-world scenarios into testing regimens, and explore how to embed AI at the heart of your development processes. Welcome to the dawn of intelligent software quality assurance.
Access to production-like data plays a crucial role in ensuring the quality and reliability of software applications. In today's dynamic software development landscape, where rapid delivery and continuous integration are paramount, effective test data strategies are more critical than ever. This article explores essential strategies and techniques for managing test data effectively, covering a range of topics from data generation and masking to validation and optimization.
Importance of realistic test data representation
Realistic test data representation is pivotal in the realm of software testing. Short, attention-grabbing paragraphs guide us through its significance. Quality test data mirrors real-world scenarios, enabling teams to identify defects, appraise performance, and guarantee software reliability. Reflecting actual user conditions ensures the software performs optimally under varied user loads.
Carefully chosen data, akin to production-like datasets, is vital for verifiable predictions and evaluations, testifying to the essence of high-fidelity data in meaningful assessments. Realistic data aids in checking negative scenarios, proactively flagging potential edge cases.
To ensure this robust representation, several strategies can be adopted:
- Integration of generative AI for data generation delivers diverse datasets, simulating real-world variations.
- The 'shift-left' approach weaves testing into earlier stages in the development cycle, improving code quality by employing high-quality data from the get-go.
- Security testing with masked data preserves privacy while maintaining the integrity needed for exploratory and automated testing activities.
A laundry list of techniques includes exploratory and database testing, highlighting the vast spectrum of testing activities that benefit from realistic data. In conclusion, diverse test data representation is the bedrock of a fruitful testing effort, making it crucial to the development of resilient and user-pleasing software.
Production data vs. real-world scenarios
In the arena of software development and testing, understanding the distinction between production data and real-world scenarios is paramount. Production data is extracted from actual operations within a live environment. However, such data may not always be at one's disposal due to privacy constraints and regulations. In contrast, production-like data is fabricated to emulate specific real-world situations that engineers and developers use during testing and development phases. This synthesized counterpart serves as a functional substitute, designed to mirror the complexities and nuances of user-generated data.
Production data brings authenticity but with limitations on usage, tied up with compliance issues. The ingenuity lies in harnessing production-like data which adheres to privacy standards and still provides a realistic testing ground. An advantage of this synthetic data is its inherent flexibility; it can be generated in varying sizes to suit the scalability needs of the testing milieu, providing ample scope for both static testing and dynamic exploration around edge scenarios.
How to make use of application data as close to real time as possible?
Access to timely data is a cornerstone of integration testing, error reduction, and efficient operations. To mirror an environment that simulates this with fidelity, enabling real-time or near real-time data access is fundamental. This necessitates automation tools adept at capturing and relaying diverse data swiftly, thus fueling innovation and meeting the appetite for cutting-edge solutions.
Data-driven enterprises demand freshness in data to electrify their endeavors. Data generation methods that produce production-like information accommodate these needs. They do so by allowing for prompt data proliferation, crucial for the calibration of reliable machine learning models, without risking privacy breaches. In the quest of maintaining quality, technology that syncs with back-end applications transmutes into a conduit for real-time test data, magnifying the realism in non-production environments.
Incorporating real-world scenarios
Embedding real-world scenarios into the development cycle fortifies the testing effort. User Acceptance Testing (UAT) environments bridge this gap, presenting users the chance to evaluate software in conditions that closely mirror production environments. This is a critical final step, collecting invaluable insights into functionality and user experience.
For a comprehensive risk assessment, these scenarios assist in preempting issues that could escape notice until they endure the scrutiny of actual use. A software's mettle is tested against a battery of inputs and conditions, thus ensuring the code's resilience. Therefore, testing environments are rigorously tailored to include varied types of input values and conditions, grounding the software's performance in reality.
Diverse test data warehouse
Envisage a test data warehouse as a repository brimming with varied and nuanced data, harboring the potential for extensive coverage. To populate such a warehouse, generative models and data automation tools are pivotal for engendering data sets that are not only vast but consistently representative of a multitude of test conditions, including those at the periphery—boundary and edge cases.
In terms of testing, a balance of positive and negative data sets in the warehouse enriches the testing landscape. Aspects of testing like reusability complement this, where a set developed for one scenario can transition smoothly into another context, promoting efficiency. Nevertheless, the integrity and precision of this data are under constant scrutiny, undergoing regular checks to uphold its contribution to high-quality software development.
Generative AI prompt based database and YAML config generator
The dawn of Generative AI has revolutionized data generation tools, arming developers and testers with the power to fabricate synthetic data that adheres to specific patterns and configurations. The introduction of prompt-based schema and a 20-table AI-driven database generator exemplifies this transformative approach to testing data. By employing Generative AI, organizations can simulate data not through mimicking database content, but by creating it anew, based on statistical properties that reflect real data.
The magic of Generative AI systems lies in their ability to maintain statistical relationships between data points, ensuring that the synthetic data used for testing is representative and mirrors the complexities of actual user data. This technological leap makes it possible to test software applications robustly before they are released to the public. Taking advantage of the Synthetic Data Vault—an open-source library—it becomes feasible to produce a prompt-based schema and a 20-table database packed with synthetic tabular data poised for rigorous testing endeavors.
Generative AI for intelligent subsetting
Intelligent subsetting speaks to a method where Generative AI can craft subsets of data that maintain the essence of a full dataset while adhering to privacy regulations. This subsetting not only aids in shielding user privacy but is also significantly effective when it comes to training machine learning models or testing software applications. Through the use of generative AI-equipped tools, organizations can streamline their testing processes with early defect detection and accelerate the development and refactoring of test cases by as much as 40%.
Generative AI synthesizes data by applying methods such as drawing numbers from distributions that closely emulate those found in the real world or by using agent-based modeling. This modeling technique creates a virtual ecosystem of agents whose interactions give rise to complex data structures, thereby mirroring their human counterparts in real-world applications.
Schema and database generation with GenAI
The future-forward capabilities of Generative AI tools, like synthesized.io, play a crucial role in the generation of production-like data for a spectrum of applications. Known collectively as GenAI, these tools facilitate the creation of realistic databases complete with detailed schema tailor-made for specific scenarios. Whether healthcare professionals need to manage medical data or airlines model the impact of flight disruptions, GenAI provides an invaluable resource.
In the finance and healthcare sectors, GenAI excels by engendering synthetic data for use in fraud detection, risk management, credit risk analysis, and even in conforming to stringent privacy regulations while managing sensitive information. Furthermore, in the realm of manufacturing, it aids in quality control and predictive maintenance by simulating real-life scenarios without compromising the integrity of actual data.
To sum up, the foundation of GenAI in creating reliable and secure testing platforms lies in its power to yield data that's not just abundant but also nuanced, ensuring a high-level of data quality and security testing without sacrificing user privacy or regulatory compliance.
Leverage AI across your testing and development organization
In today's fast-paced development cycle, leveraging AI in testing and development organizations is pivotal for ensuring high-quality software outcomes. Generative AI tools have revolutionized the testing landscape, reducing bugs by a notable 40 percent and streamlining the test case development process. The use of synthetic test data is a game-changer, allowing teams to simulate real-world data without compromising on security or privacy.
Organizations can further amplify their testing efforts by adopting AI governance to manage test data generation, thus enabling the simulation of complex scenarios and enhancing test coverage. Best practices in software engineering stress the importance of extensive testing - from unit and integration tests to proactive input drift detection - to guarantee the dependability of AI systems.
Adopting a 'shift-left' approach to testing, where testing is performed earlier in the development process, is also instrumental. It not only improves code quality but also speeds up the testing effort. By incorporating AI and automation tools, teams can expedite testing activities, including exploratory and database testing, while ensuring diverse and realistic test data representation.
Key Methods for AI-based Test Data Generation:
- Generative AI for Data Generation: Produces high-fidelity, production-like data.
- Exploratory Testing: Uses AI to discover edge cases.
- Automated Testing Activities: Integrates machine learning models for dynamic input values.
Understanding test data management challenges
- Feedback Loops: Discuss the importance of feedback loops in refining AI algorithms for test data generation, enabling continuous improvement in data quality and diversity.
- Testing Team Collaboration: Highlight the collaboration between AI experts, data scientists, and testing teams in developing AI-powered test data generation solutions.
- Ingestion Testing: Explain how AI can facilitate ingestion testing by generating realistic datasets to validate data ingestion processes effectively.
- Reduced Cost: Illustrate how AI-driven test data generation can lead to cost savings by automating manual testing processes and minimizing errors in production.
Best practices for AI-driven testing
Remember, a testing environment enriched with AI not only fosters a culture of high-quality data but also enhances the overall approach to testing across non-production environments.
- Effective Testing Practices: Highlight best practices in AI-driven test data management, including data anonymization techniques, data quality validation, and compliance with regulatory standards.
- Automated Testing Processes: Showcase how AI-powered test data generation automates testing processes, streamlining regression testing, and ensuring consistent test execution.
- Ethical and Legal Implications: Discuss the ethical and legal considerations surrounding AI-driven test data generation, such as data privacy concerns and adherence to industry regulations.
- Bugs in Production: Illustrate the consequences of overlooking test data quality and diversity, leading to the occurrence of bugs and errors in production environments.
AI-powered test data generation techniques
- Popular Techniques: Explore popular AI techniques such as generative adversarial networks (GANs), deep learning, and natural language processing (NLP) used for test data generation.
- Combinatorial Testing: Discuss how AI algorithms can efficiently generate test datasets covering a wide range of input combinations, facilitating combinatorial testing.
- Complex Test Infrastructures: Address the challenges of managing complex test infrastructures and how AI can optimize test data generation within such environments.
- Rapid Feedback: Emphasize the role of AI-driven test data generation in providing rapid feedback to development teams, enabling quick iteration and improvement.
Building towards a future of intelligent test data provisioning
In the rapidly evolving landscape of software development, the demand for robust, reliable, and high-quality software is ever-present. At the heart of this endeavor lies the need for diverse, representative, and production-like test data. Synthesized.io is pioneering the development of a cloud-native, code-first, AI-driven developer platform for database environment management. This revolutionary platform empowers engineering teams to ship great software rapidly without grappling with the complexities of database management. By integrating AI-driven test data generation into their workflows, developers can ensure comprehensive testing coverage without the overhead of managing complex test infrastructures. With Synthesized.io leading the way, the future of software development is brighter than ever before. By harnessing the power of AI, developers can unlock new possibilities and push the boundaries of innovation. Together, we are building a world where software development is efficient, reliable, and accessible to all. Welcome to the future of intelligent software quality assurance.
Where to go from here?
- Explore Synthesized.io's AI-driven test data generation platform to streamline your testing workflows.
- Embrace a 'shift-left' approach to testing, integrating testing into earlier stages of the development cycle for improved code quality.
- Engage in continuous learning and experimentation with AI-powered testing techniques to stay ahead of the curve.
- Collaborate with AI experts, data scientists, and testing teams to develop custom AI solutions tailored to your specific testing needs.