When French painter Rene Magritte was 30 he painted this picture of a pipe. With the caption, “this is not a pipe,” he provocatively depicted the philosophical question of what “real” truly means. Incorporating this idea into the modern age of data we can explore some similar concepts.

What makes data real or fake? What makes data synthetic? Is all data real or is it all fake? I think it’s interesting to ponder on these questions as we explore the blurred lines of “original” & “synthetic” data to learn how synthetic data will enable the next generation of enterprise machine learning models and software testing to succeed.
I will discuss the topic of synthetic data, and why it is emerging as the key to better enterprise ML & software testing. To elaborate further let me give context to data in the current age and highlight the three sections of this blog.
Data is growing at an exponential rate - it’s expected to hit 175+ zettabytes worldwide by 2025. We’re seeing a shift from heavily centralized data strategies that companies have been investing in and trying to deliver over the last 5-10 years to a more agile development architecture.
In the ideal world:
- Data needs to be readily available by the teams that need it
- Data needs to be flexible and easily used for the specific task at hand (for testing or third parties)
- Teams should not have to suffer from approval delays
Yet the current situation is different. Original data doesn’t fulfill these requirements. Here are three problems we've identified where synthetic data is the key to the solution:
1. Data Privacy
With increasing privacy requirements, customers say it can take from 4-20 weeks to safely and compliantly access sensitive data, making development cycles extremely slow. In organizations operating across multiple countries, data is siloed and ownership can be in the wrong place, which means collaboration between distributed teams and more frequently with external partners is complex at best (sometimes it’s impossible).
2. Data Quality
ML models are only as good as the data they are trained on. While we may have access to larger volumes of data, that is not necessarily an ideal scenario, as large amounts of data make it difficult to maintain quality as humans can't comprehend the entire scope of the data. This impacts their ability to assess their data’s utility.
3. Data Bias
We see growing examples of unfair AI propagating discrimination in society. As our models become more prominent and powerful the bias within data is having more significant consequences in the real world. In our experience, synthetic data offers a solution to these three problems among many others.
But First, What Is Synthetic Data?
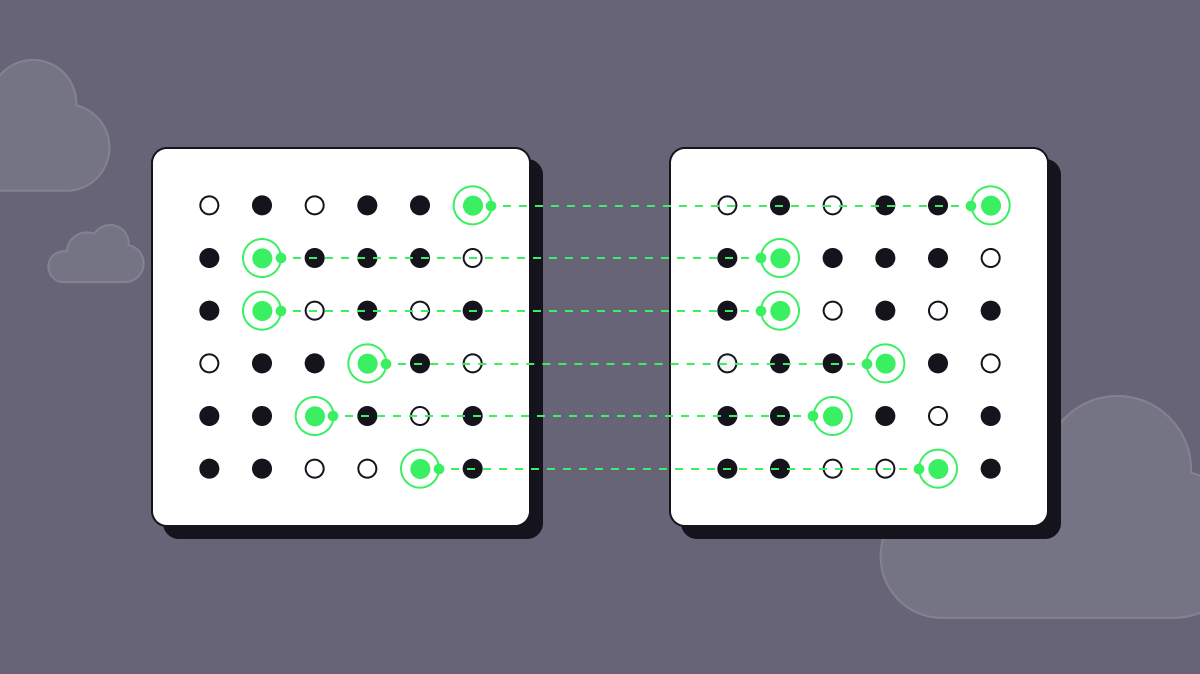
Just as Rene did with his painting (separating the physical construct of a pipe from the idea or thought that the pipe conveyed) what if we separate the physical bits of data from the signals of information it conveys. What if we could pull apart the trends and insights from the individual rows of data which they are made from? In other words, what if we didn’t use the original data to represent real-world behavior?
If I want data showcasing a trend in customer behavior, it doesn't need to be the actual customer data. I can instead use data that looks and “feels” similar to the original data, but each row is entirely new with no 1-to-1 mapping back to the original data.

This is what synthetic data is. Data that hasn't been measured directly. It doesn’t have a 1-to-1 mapping with real-world data. There are many ways in which it can be made using statistical or deep-generative models such as:
- Variational Autoencoders
- Generative Adversarial Networks,
- Hidden Markov Models
Just to name a few.
Importantly, each of these models works by taking some original input data, developing an understanding of the global properties and information in the data, and then using this learned understanding to generate new highly representational synthetic data. These generative models can be augmented to amplify or filter different signals of information within a dataset, and they help to separate the notion of global information from the individual data points.
With synthetic data as a tool, we are then equipped to solve some of the growing problems with original data. Let's now take a look more closely at the three challenges I highlighted earlier:
The Problem with Data Privacy
There are a variety of techniques that are currently used to preserve privacy. The objective is always to make it impossible to connect Personally Identifiable Information (PII) to an individual. The drawback of traditional anonymization is that no matter which technique is used, There’s still a 1-to-1 mapping between the original data and the masked data. And so there is a chance it can be reversed using analytical techniques such as attribute inference or linkage attacks.
The bottom line is that while de-identification hides data, the real data is still there.
Several widely-cited real-world examples have come to light where traditional anonymization simply wasn't enough. In those incidents, the data had been anonymized but re-identification of individuals was possible.
A well-known example was in 2006 with the Netflix prize dataset. It was demonstrated that an adversary who knows only a little bit about an individual subscriber could easily identify this subscriber’s record in the dataset. Consequently, it was possible to uncover these subscribers’ apparent political preferences and other potentially sensitive information.
We need to separate the global aggregate information of the dataset from the confidential information of any given individual. This brings us to the emerging alternative to the data anonymization puzzle, which is privacy-preserving synthetic data. Without the constraints of a 1-to-1 mapping with the original data, synthetic data allows us to adopt a framework of differential privacy where an individual's data is mathematically guaranteed to be uncertain up to some configurable value.
Even with this framework, there is increasing evidence that models claiming to follow differential privacy techniques are still susceptible to data linkage. The reality is that it's difficult to truly synthesize data that preserves privacy.
For comfort, we turn to a real example of where synthetic data was successfully used in a privacy-preserving manner to illustrate this point.
During the Covid pandemic in 2019, when the UK government offered stimulus funding, cases of financial crime spiked. Transactional bank fraud is a notoriously difficult and complex problem to address. Collaboration within the same company or government body is often slow or impossible due to the highly controlled customer records.
The Financial Conduct Authority in the UK created a digital sandbox to help tackle this challenge. In this sandbox, Synthesized was used to provide a synthetic copy of confidential transactional data that the teams were able to use almost immediately. The data was both assessed to be privacy-preserving and of high quality, as vetted by The Alan Turing Institute, and successfully enabled collaboration.
The Problem with Data Quality
I mentioned earlier that the amount of data in the world is expected to be over 175 zettabytes by 2025, which is a lot. It works out to be about 2.5 quintillion data bytes each day, which is too much for any data scientist or ML engineer to comprehend. This subsequently poses issues of how data scientists maintain quality. The vast volume of big data makes it difficult to have humans in the loop to assure data quality. And the variety of data makes it difficult to manually design rules that handle anomalies in big data.
Our limited capacity to identify patterns in high-dimensional data leaves us inept at understanding and recognizing the different kinds of failures that are possible in data. We are too limited in our awareness to be able to foresee how any given data point can impact the complicated systems which we design.
Synthetic data offers the possibility of wrangling such large amounts of data by considering the different use cases of the data and creating optimally-sized synthetic datasets which perform even better at their task at hand. Instead of maintaining big data, it becomes maintaining insights.
Take the case of using data for white-box testing. We need enough input data to cover all the cases and functionality of the system at hand. In an ideal world, production data would be used to test such a thing. In reality, production data is normally inaccessible, incomplete, and unnecessarily large for the purpose of testing a system. This makes testing an expensive task to complete.
At Synthesized we found that generative modeling can be applied to production databases to produce privacy compliant (and therefore accessible), high-coverage synthetic databases which are capable of capturing complex intra-table behavior and preserving referential integrity.
One of our clients, a leading insurance group, found software testing a recurring challenge. First, they were not able to use production data in testing and the process of creating mock data was taking considerable time and resources. Secondly, the group did not have the capability to guarantee full coverage of all of its test scenarios. They were looking for a way to increase coverage while decreasing the resources and effort needed for testing.

By analyzing the SQL logs of their application in order to understand all logical branches to be covered by the test data we were able to automate the process of generating a synthetic database which increased test coverage from 50% up to 100%. Additionally, the dataset size was reduced to 20% of the original size. Synthetic data was able to provide 100% test coverage within minutes, reduce the test data size, and therefore the test run time all the while being privacy compliant by design.
The Problem with Data Bias
Regarding the problem of data bias, according to IBM’s ‘Global AI Adoption Index 2021, 58% of organizations have admitted that building models on data that has inherent biases were one of the biggest barriers to developing trusted AI.
But, the real world is biased and unfair. Even if we collect our data perfectly, it is likely that there are still biases contained within. What makes matters worse is that these biases are proceeding to impact more and more significant decisions being made by AI.
Discriminatory decisions are subsequently impacting society and propagating the pre-existing biases prevalent around the world. This circle of bias needs a circuit breaker. At the end of 2017, data scientists in Chicago used hospital data to predict the length of stay of patients. They discovered that one of the best predictors for the length of stay was the person’s postal code. The postal codes that correlated to longer hospital stays were in predominantly poor neighborhoods.
If optimizing hospital resources was the sole aim of their program, people’s postal codes would clearly be a powerful predictor of the length of hospital stay. But using them would divert hospital resources away from marginalized communities, exacerbating existing biases in this system. All are achieved with the good intention of improving healthcare.
Another great example is Amazon’s hiring algorithm which they first implemented in 2014. The company’s experimental hiring tool used Artificial Intelligence to give job applicants scores ranging from one to five stars. However they uncovered a big problem, their new recruiting engine did not like women.
In effect, Amazon’s system taught itself that male candidates were preferable. It penalized resumes that included the word “women’s,” as in “women’s soccer club captain.” And it downgraded graduates for including all-women colleges on their resumes. These examples simply reiterate the issue of working with big data, as it’s hard to fully comprehend all of its effects.
Yet, the continued toll of data breaches and leaks demonstrates that industries are still stuck with a more basic problem of understanding that there’s a problem at all. Before we consider how we can use tools such as synthetic data to combat data bias, we need to first measure it.
And that's why, at Synthesized, we've developed an open-source project, Fairlens, which focuses on enabling data scientists to gain a deeper understanding of their data, and on helping them to employ fair and ethical usage of data in analysis and machine learning tasks. Importantly, we aren’t defining bias on our own; we are enabling an environment for anyone to contribute their definitions of fairness. So that anyone can get involved, and contribute towards fairer data practices. From the measures defined within Fairlens, we have seen that synthetic data offers ways to remediate and mitigate the biases recorded. Synthetic data can be used to break the propagating circle of bias in data-driven systems.
Having discussed some of the problems with data that we are seeing globally, from accessing confidential data, maintaining high-quality data, and dealing with biases that are ever-present in data & society, as well as the ways that synthetic data can be used to solve these problems, it’s clear to me that synthetic data serves as the key to better enterprise ML & software testing. And it's no wonder why Gartner predicts that synthetic data will likely drive almost everything we do in less than a decade.

Back to Magritte's painting of the pipe. I want to leave you with the image of another painting that sold for nearly half a million dollars in 2018. Now the painting is not a person, nor is it a portrait of a person, it’s synthetic data. Be ready to see a whole lot more of it.