







If you have ever needed to run automated tests, it is likely that at some point you will have run into Testcontainers. When this Java library was introduced in 2015 by AtomicJar, it transformed test automation by allowing developers to run integration tests in a CI/CD pipeline or even on their own machines, rapidly decreasing the time needed to run tests. A key component of using Testcontainers effectively is the Testcontainers database setup.
Input data is vital to conducting reliable integration testing. Test data often needs to be prepared before running test cases and, with growing volumes of data and data compliance regulations, using copies of production data becomes expensive and sometimes simply impossible. With DevOps automation, there is a need for an API-driven test data generation directly in a test environment as part of a CI/CD pipeline.
By combining Testcontainers with Synthesized’s Testing Data Kit (TDK), developers can populate any Testcontainers database with synthetically generated data, enabling rapid development of tests for logic which involves interaction with the database, while avoiding the need to develop and maintain huge amounts of code.
How it works
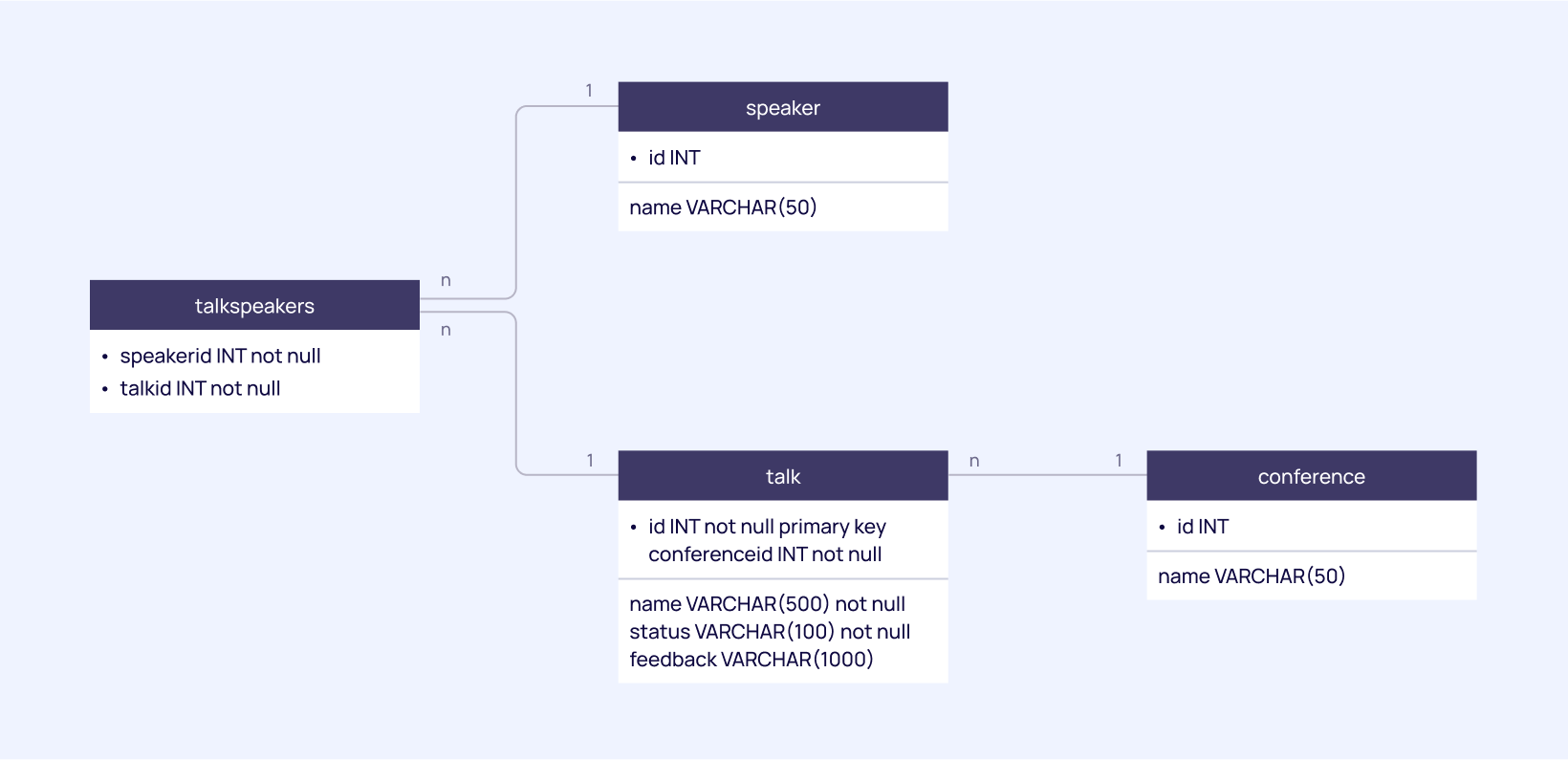
To illustrate how the integration of Synthesized TDK and Testcontainers databases works, we are going to consider a toy backend project built with a common technology stack: Java, SpringBoot, and Spring JDBC module which uses PostgreSQL as its database. Our toy application is going to automate scheduling of talks and participants for a large tech conference, and hence store the information about conferences, speakers and their talks. The PostgreSQL database has a rather simple schema:
Traditionally, there were two approaches to deal with creating test data: 1. Maintaining an initialization script which pre-populates a database with records, and 2. Inserting test-specific records during the setup phase of the test using the so-called ‘fixture factories’. Both approaches require maintenance of the significant amount of code and thus time to write the actual tests. Now, instead of maintaining an ‘initialization script’, Synthesized TDK is able to initialize all the tables in the Testcontainers database with the records.
First, add a test dependency via Maven Central.
<dependency>
<groupId>io.synthesized</groupId>
<artifactId>tdk-tc</artifactId>
<version>1.01</version>
<scope>test</scope>
</dependency>tdk-tc is a small MIT-licensed library which acts as a wrapper for a freely-distributed version of Synthesized TDK running in a Docker container. It provides a simple class SynthesizedTDK which requires two JdbcDatabaseContainer to prepare a test database. If we are using SpringBootTest we can make the preparation of the test Testcontainers database as a part of our @TestConfiguration.
Now, you should define a configuration to prepare your test database.
Given that PostgreSQLContainer<?> input is an empty database with deployed schema (you can obtain such container using a simple DDL script or migrations library, such as Flyway or Liquibase) and PostgreSQLContainer<?> output is a totally clean database, you can produce a database pre-filled with random data using SynthesizedTDK (note that both containers are created in the same network):
private PostgreSQLContainer<?> getContainer(String name, boolean initData) {
...
}
network = Network.newNetwork();
input = getContainer("input", true);
output = getContainer("output", false);
Startables.deepStart(input, output).join();
new SynthesizedTDK()
.transform(input, output,
"""
default_config:
mode: "GENERATION"
target_row_number: 10
global_seed: 42
""");The first two arguments of the transform method are input and output containers. The third one is a YAML string containing parameters of data generation. Synthesized TDK requires a configuration which is described in detail here. You can set up generation parameters for each specific table and field. However, if you don’t do that, Synthesized TDK will use reasonable defaults. Most likely the given example will work for your Testcontainers database schema.
Two essential parameters that we need to understand are:
- target_row_number defines the desired number of records generated for each table.
- global_seed is a seed for random value generators. The result of generation will be the same each time the generation is being run with the same seed, schema and workflow configuration.
Note that in order to have a non-empty test database we don’t need a full insertion script anymore! Just by choosing a constant RNG seed we can be sure that the resulting data in the Testcontainers database will be the same each time SynthesizedTDK.transform(…) is being executed.
When output database is ready, we can create a data source that will be used in the test, e. g. declaring a respective @Bean in our @TestConfiguration:
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl(output.getJdbcUrl());
config.setUsername(output.getUsername());
config.setPassword(output.getPassword());
return new HikariDataSource(config);
}Now let’s get consider our method under test:
public Set<Talk> getTalksByConference(Conference conference)We need a conference object as an input, and then we need to compare a result with some reference value.
Since our database is non-empty and consistent, we may use our own DAO classes to get a first conference we come across:
//The object under test
@Autowired
private TalkDao dao;
//The object needed to get a conference
@Autowired
ConferenceDao conferenceDao;
private Conference conference;
@BeforeEach
void init() throws SQLException {
conference = conferenceDao.getConferences().iterator().next();
}This is effectively all the "arrange" part of the test. Since data generation is deterministic, the conference (and its relation with all the other objects) will be the same across runs of the test.
The "act" part is a single-liner:
@Test
void getTalksByConference() {
//Act
Set<Talk> talks = dao.getTalksByConference(conference);
//Assert
JsonApprovals.verifyAsJson(talks);
}What about the "assert" part? As the generation is deterministic, we may figure out the actual properties of the returned Set<Talk>, and then add assertions. However, there is a simpler way to do this with Approval tests. In short, Approvals library creates a snapshot of our Set<Talk> serialized as JSON and stores it in a text file in your test code folder. In our case, the output looks like this:
[
{
"id": 9,
"name": "talk1",
"conference": {
"id": 3,
"name": "conf1"
},
"status": "IN_REVIEW",
"speakers": [
{
"id": 9,
"name": "speaker2"
}
]
}
]Judging from this file, we may conclude that our method indeed returns a set of talks with "conference" and "speakers" properties set. This file should be committed to the source control and it will be used each time the test is run to ensure that the result is not changed.
Note that we put very little or zero effort in order to write 'arrange' and 'assert'. Thus using Synthesized TDK we can significantly cut time on writing the tests.
Of course, we can assert more on the returned value, e.g. check that the returned talks are actually belong to the conference:
for (Talk talk : talks) {
assertThat(talk.getConference()).isEqualTo(conference);
}In the example above we just verified the ability of the method to extract data from the database, which doesn’t involve complex business logic.
We can also look at another interesting use case. Imagine that we have a service class TalkService that deals with statuses of talks, and we want to check the fact that no talk can be moved to “rejected” status without attaching a feedback.
For this test scenario we need a talk with a predefined state. We can do the following: pick up any talk from the database and change its state to the desired. Here we test that a talk with non-empty feedback can be moved to “rejected” status:
@Test
void rejectInReviewWithFeedback() {
//Arrange
dao.updateTalk(talk.withStatus(Status.IN_REVIEW)
.withFeedback("feedback"));
//Act
service.changeStatus(talk.getId(), Status.REJECTED);
//Assert
Assertions.assertThat(dao.getTalkById(talk.getId()).getStatus())
.isEqualTo(Status.REJECTED);
}In this test we verify that an attempt to reject a talk with an empty feedback raises an exception:
@Test
void doNotRejectInReviewWithoutFeedback() {
//Arrange
dao.updateTalk(talk.withStatus(Status.IN_REVIEW)
.withFeedback(""));
//Act, Assert
Assertions.assertThatThrownBy(() ->
service.changeStatus(talk.getId(), Status.REJECTED))
.hasMessageContaining("feedback");
Assertions.assertThat(dao.getTalkById(talk.getId())
.getStatus()).isEqualTo(Status.IN_REVIEW);
}Conclusion
To try Synthesized TDK with Testcontainers database, check out the demo project here. All code samples are taken from that project. Follow a readme file in order to run demo tests.
To use TDK as a standalone application, read the docs here. You can embed the TDK into your CI/CD pipeline to create test databases based on sample production databases. You can choose between a number of techniques to prepare data:
- Subsetting
- Masking
- Generation
There is a number of masking and generation methods available, you can find them out here.
FAQs
What are the benefits of using a Testcontainers database with Synthesized TDK?
Using a Testcontainers database with Synthesized TDK offers several benefits, including rapid setup of test environments, consistent and reproducible test data generation, and reduced maintenance of initialization scripts. By using synthetically generated data, developers can ensure their tests are reliable and can quickly adapt to changes in the database schema without the need for manual updates.
How does Synthesized TDK improve the efficiency of database testing?
Synthesized TDK improves efficiency by automating the generation of test data for your Testcontainers database. This eliminates the need for manually maintaining test data scripts and ensures that the data is consistent across different test runs. This allows developers to focus more on writing test logic rather than data preparation.
Can Synthesized TDK handle complex database schemas in Testcontainers?
Yes, Synthesized TDK can handle complex database schemas within Testcontainers database setups. It allows for detailed configuration of data generation parameters for specific tables and fields. This flexibility ensures that even databases with intricate relationships and dependencies can be populated with relevant test data, making the testing process more robust.
How do you integrate Synthesized TDK with a CI/CD pipeline for Testcontainers?
Integrating Synthesized TDK with a CI/CD pipeline involves adding it as a dependency in your project and configuring it to work with your Testcontainers database. During the CI/CD pipeline execution, Synthesized TDK can generate and populate the database with synthetic data, ensuring that each test run starts with a consistent and predefined state. This integration helps maintain test reliability and reduces setup time.
What are some common use cases for using Synthesized TDK with Testcontainers database?
Common use cases include automating integration tests that involve database interactions, testing business logic that relies on consistent and reproducible data, and verifying the behavior of applications under various data conditions. By using Synthesized TDK with a Testcontainers database, developers can simulate real-world scenarios and ensure their applications handle different data states effectively.
